
在传统服务器芯片市场,英特尔是个巨无霸,无论是IBM Power还是ARM阵营,所占有的份额都微乎其微。但战线转移到人工智能领域,IBM似乎更有优势。
据外媒报道,近日IBM和NVIDIA联手推出了新服务器IBM Power Systems S822LC for High Performance Computing(还有两款产品分别为IBM Power Systems S821LC和IBM Power Systems S822LC for Big Data),从这一串名字可看出,这并不是一款普通的服务器,它是专门为人工智能、机器学习和高级分析应用场景而推出的。
IBM官方宣称,这款服务器数数据处理速度比其它平台快5倍,和英特尔x86服务器相比,每美元的平均性能高出80%。

这款服务器比英特尔x86强在哪?
据了解,该款服务器使用了两个IBM Power8 CPU和4个NVIDIA Tesla P100 GPU。Power8是目前IBM最强的CPU,从之前媒体的评测数据来看,其性能是要优于英特尔E7 v3的,而Tesla P100是NVIDIA今年才发布的高性能计算(HPC)显卡,这样的配置组合在处理性能上自然不弱。
原因有两个:
其一,相比CISC指令集,采用的RISC指令集的Power处理器可同时执行多条指令,可将一条指令分割成多个进程或线程,交由多个处理器同时执行,因此并行处理性能要优于基于CISC架构的英特尔x86芯片。
另外,这款服务器的巧妙之处还在于Power8和Tesla P100之间的“配合”。
Power架构的另一大特点就是具有充分发挥GPU性能的优势。
实际上,Tesla P100有两个版本,一个是NVIDIA今年4月推出的NVLink版,另一个是6月发布的PCI-E版本,简单来讲,前者是后者的加强版,与IBM Power8配对的正是Tesla P100 NVLink版。
Tesla P100采用的是Pascal架构,能够实现CPU与GPU之间的页面迁移,不过每块NVLink版还配置了4个每秒40 GB NVIDIA NVLink端口,分部接入GPU集群。NVLink是OpenPOWER Foundation独有的高速互连技术,其有效带宽高达40GB/S,堪称PCIE的升级版,足以满足多芯片并行计算的需求。不过支持这一标准的CPU屈指可数,Power8则是其中之一(英特尔不在此之列)。
这就意味着,Power8 CPU能够和Tesla P100 GPU以更高的速度完成通信,这一特性可让IBM Power Systems S822LC for High Performance Computing中的CPU和GPU之间的连接速度远快于普通的在PCIe总线上交换数据的表现。
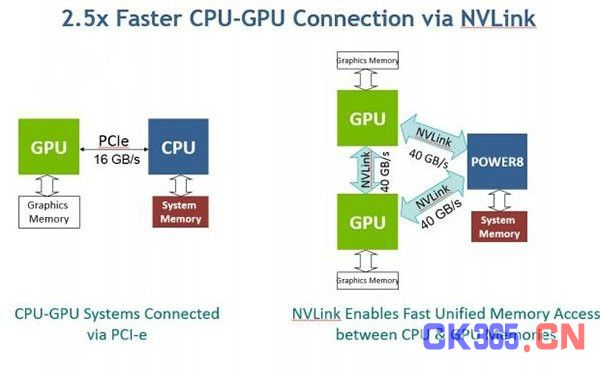
IBM表示,“这一功能意味着,不同于在GPU处于PCI-E界面上的x86系统上,数据库应用程序、高性能分析应用程序和高性能计算应用程序运行能够在要大得多的数据集上运行。”
另外,Tesla P100的半精度浮点运算性能达到了每秒21万亿次 —— 比插入现代PCI-E插槽的GPU高出大约14%,这样的处理能力对训练深度神经网络的重要性不言而喻。
IBM还做了个纵向对比,和老款Power S822LC服务器的Tesla K80 GPU加速器相比,新款服务器的加速能力提升了两倍多。
预计明年问世的IBM Power9会延续对CPU+GPU组优化。
为何是“CPU+GPU”?
众所周知,在人工智能人工智能和深度学习等计算任务上,CPU早已不堪重任。因此,不少企业纷纷推出人工智能专用芯片概念,例如谷歌的TPU(Tensor Processing Unit);还有业内人士力挺FPGA更适合深度学习的算法,这也是英特尔以高价收购Altera的主要原因。
不过,上述两个替代CPU的方案都还未成熟,目前大多数企业采用的依然是“CPU+GPU”的组合,或者称为异构服务器。通常来说,在这种异构模式下,应用程序的串行部分在CPU上运行,而GPU作为协处理器,主要负责计算任务繁重的部分。
因为和CPU相比,GPU的优势非常明显:
1.CPU主要为串行指令而优化,而GPU则是为大规模的并行运算而优化。所以,后者在大规模并行运算的速度更快;
2.同等面积下,GPU上拥有更多的运算单元(整数、浮点的乘加单元,特殊运算单元等等);
3.一般情况下,GPU拥有更大带宽的 Memory,因此在大吞吐量的应用中也会有很好的性能。
4.GPU对能源的需求远远低于CPU。
当然,这并不代表人工智能服务器对CPU没有需求,CPU依然是计算任务不可或缺的一部分,在深度学习算法处理任务中还需要高性能的CPU来执行指令并且和GPU进行数据传输,同时发挥CPU的通用性和GPU的复杂任务处理能力,才能达到最好的效果,通俗点说就是实现CPU和GPU的协同计算。
虽然NVIDIA和Intel等芯片商正在为GPU和CPU孰强孰弱陷入了口水战,但实际上这些企业已经开始在异构计算上加大了研发力度,至少在近期内,CPU和GPU的结合将继续成为人工智能领域最有效的方案。






