“语音识别”的终极梦想,是真正能够理解人类语言甚至是方言环境的系统。但几十年来,人们并没有一个有效的策略来创建这样一个系统,直到人工智能技术的爆发。
在过去几年中,人们在人工智能和深度学习领域的突破,让语音识别的探索跨了一大步。市面上玲琅满目的产品也反映了这种飞跃式发展,例如亚马逊Echo、苹果Siri 等等。本文将回顾语音识别技术领域的最新进展,研究促进其迅猛发展进程的元素,并探讨其未来以及我们距离可以完全解决这个问题还有多远。
背景:人机交互
多年来,理解人类一直都是人工智能的最重要任务之一。人们不仅希望机器能够理解他们在说些什么,还希望它们能够理解他们所要表达的意思,并基于这些信息采取特定的行动。而这一目标正是对话式人工智能(AI)的精髓。
对话式AI包含有两个主要类别:人机界面,以及人与人沟通的界面。在人机界面中,人类与机器往往通过语音或文本交互,届时机器会理解人类 (尽管这种理解方式是有限的) 并采取相应的一些措施。图1表明,这台机器可以是一个私人助理 ( Siri、Alexa之类的产品 ) 或某种聊天机器人。
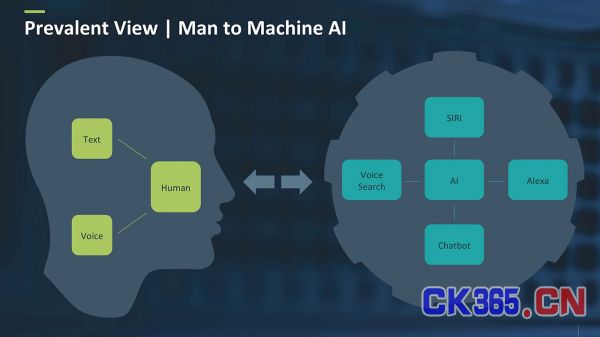
图1:人机交互AI
在人与人之间的互动中,人工智能会在两个或两个以上进行会话、互动或提出见解的人类用户之间构建一座桥梁 ( 参见图2 ) 。例如,一个AI在听取电话会议后,能够创立出一段简要的电话记录摘要,并跟进相关人员。
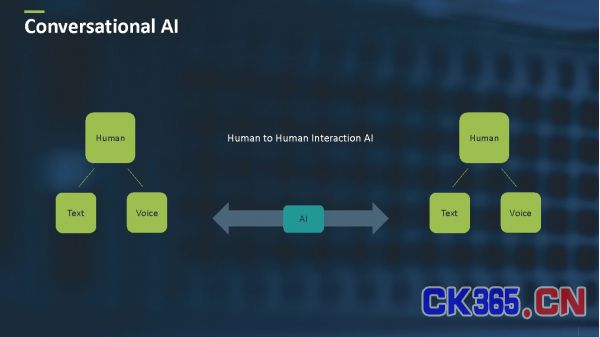
图2:人与人之间互动的人工智能
对话式AI背后:机器感知与机器识别
为了理解对话式AI背后的挑战与技术,我们必须研究人工智能的基本概念:机器感知与机器识别。
机器感知是指机器能够采用类似于人类自己凭感觉感知周围世界来分析数据的能力;换句话说,其本质上就是为机器赋予人类的感知能力。近来很多的人工智能算法都需要使用电脑摄像头,如目标检测和识别,都归属于机器感知范畴——主要涉及视觉处理。语音识别和分析则是那些利用听觉的机器感知技术。
机器识别是在机器感知所生成的元数据之上的推理运算。机器识别包括决策制定、专家系统、行动执行以及用户的意图等方面。一般情况下,如果没有机器识别,对AI的感知系统不会产生任何影响,而机器感知会提供适当的元数据信息来令其做出决策与执行行动。
在对话式AI中,机器感知包括所有的语音分析技术,如识别和性能分析;机器识别则包括所有与语言理解能力相关的技术,而这也是自然语言处理 ( NLP ) 的一部分。
语音识别的发展
语音识别的研究和发展情况基本分为三个主要时期:
2011年之前
人们对语音识别的活跃研究已经进行了几十年,而事实上,即使是在二十世纪50年代和60年代,人们也一直在试图构建语音识别系统。然而,在2011年以及深度学习、大数据和云计算出现以前,这些解决方案还远远不足以被大规模采用以及商业使用。从本质上来说,其算法还不够好,当时也没有足够的数据可以用于算法的训练,而且无法进行高性能计算机也阻碍了研究人员运行更复杂的实验。
2011年-2014年
深度学习产生的第一个重大影响发生在2011年,当时有一个研究小组一同创造了第一个基于深度学习的语音识别系统,而这个研究小组成员包括来自微软的研究人员、李登(Li Deng)、董玉(Dong Yu)和亚历克斯·阿赛罗(Alex Acero),以及杰弗里·希尔顿(Geoffrey Hinton)和他的学生乔治·达尔(George Dahl)。效果很即时:其相对错误率降低了25%以上。而这个系统也是深度学习领域进行大规模发展和改进的切入点。
此后,在有了更多数据、云计算可用后,苹果(Siri)、亚马逊 (Alexa) 和谷歌这类的大公司均采用了深度学习技术,而且对其产品性能有着显著的改善,并将其产品发布到了市场上。
2015至今
在2014年底,递归神经网络获得了更多的关注。与此同时,递归神经网络与注意力模型、记忆网络以及其他技术一起,掀起了这个领域发展的第三次浪潮。如今,几乎每一种算法或者解决方案都采用了某种类型的神经模型,而且实际上,几乎所有的关于语音的研究都已转向深度学习。
语音识别领域,神经模型的最新进展
过去六年中,语音识别在此前40多年的基础上创造了更多的突破。这种非凡的新进展主要归功于神经网络。要理解深度学习所带来的影响以及它所扮演的角色,我们首先需要理解语音识别是如何工作的。
尽管近50年来语音识别一直属于热门研究领域,然而构建能够理解人类语言的及其仍旧是人工智能最具挑战性的问题之一,要实现这一目标非常困难。语音识别由不少明确的任务组成:给出某种制定的人类语言,然后尝试将其语音转换成文字。然而,机器所识别的语音中可能包括一部分噪音,所以就要求其能够从噪声中提取出与对话相关的部分并将其转换成有意义的文字。
语音识别系统的基本构造块
语音识别基本分为三个主要部分:
信号位准:信号为准的目的是提取语音信号并增强信号(如果有必要的话),或是进行适当的预处理、清理和特征提取。这非常类似于每一项机器学习任务,换句话说,如果给定一些数据,我们需要做适当的数据预处理和特征提取。
噪音位准:噪音位准的目的在于将不同的特征划分成不同的声音。换句话说,声音本身并不能提供出一个足够精确的标准,而有时我们将次于原声的声音称为声学标准。
语言位准:因为我们假设这些声音都是人类所产生而且是有意义的,因此我们可以把这些声音组合成词语,然后把这些词语组合成句子。在语言位准中,这些技术通常属于不同类型的NLP技术。
基于深度学习的改进
深入学习对语音识别领域产生了巨大的影响。其影响非常深远,即使在今天,几乎每一个语音识别领域的解决方案都可能包含有一个或多个基于神经模型的嵌入算法。
通常而言,人们对语音识别系统的评价都基于一个名为配电盘(SWBD)的行业标准。SWBD是一个语音语料库,整合了电话中的即兴对话,包含音频和人声的副本。
语音识别系统的评估标准主要基于其误字率(WER),误字率是指语音识别系统识别错误的单词有多少。图3展示了从2008年到2017的误字率改进情况。
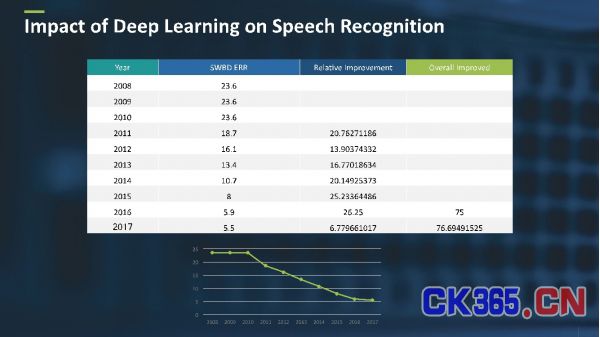
图3:误字率改进情况
从2008年到2011年,误字率一直都处于一个稳定的状态,位于23%至24%之间;而深度学习从2011年开始出现时起,误字率从23.6%降低至5.5%。这一重大发展对语音识别开发而言是一种变革,其误字率的改进相对提高了近77%。误字率的改善也产生了广泛应用,例如苹果Siri、亚马逊 Alexa、微软 Cortana 和 Google Now,这些应用也可以通过语音识别激活各种家居,如亚马逊Echo 和 Google Home。
秘密武器
那么,系统产生如此大幅度改善的原因是什么呢?是不是有什么技术可以使得误字率从23.6%减少到了5.5%呢?遗憾的是,并没有其他单独的技术、方法。
然而,深入学习和语音识别息息相关,构造出了一个可以涉及各种不同技术和方法的先进系统。
例如,在信号位准中,有着不同的基于神经模型从信号中提取和增强语音本身的技术 (图4) 。同时,还有能够用更加复杂高效的基于神经模型的方法取代经典特征提取方法的技术。
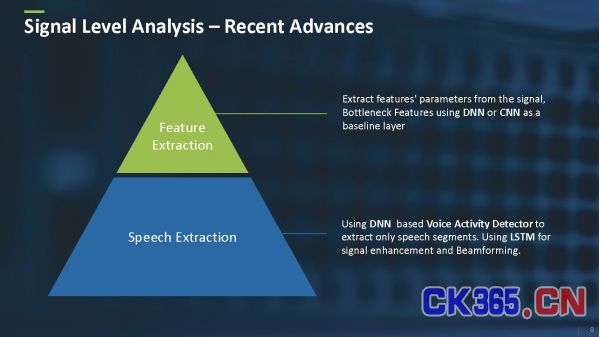
图4:信号位准的分析
声音和语言位准中也包含有各种各样不同的深度学习技术,无论是声音等级分类还是语言等级分类,都采用了不同类型基于神经模型的架构(见图5)。

图5:声音和语言位准分析
总而言之,建立一个先进的系统并不是一项容易的工作,而实现将所有涉及的这些不同技术集成为一个系统的过程也不轻松。
前沿研究
近来在语音识别领域有这么多的突破,那么我们自然要问,语音识别接下来的突破口在哪?未来聚焦的研究点或将从以下三个主要领域展开:算法、数据和可扩展性。
算法
随着亚马逊Echo 与 Google Home 的成功,许多公司正在发布能够识别理解语音的智能扬声器和家庭设备。然而,这些设备的推出又带来了一个新问题:用户说话时往往距离麦克风不是很近,例如用户用手机对话时的状态。而处理远距离语音识别又是一个具有挑战性的问题,很多研究小组也正在积极研究这个问题。如今,创新的深度学习和信号处理技术已经可以提高语音识别的质量了。
数据
语音识别系统的关键问题之一是缺乏现实生活的数据。例如,很难获得高质量的远程通话数据。但是,有很多来自其他来源的数据可用。一个问题是:我们可以创建合适的合成器来生成培训用的数据吗?今天,生成合成数据并培训系统正在受到重视。
为了训练语音识别系统,我们需要同时具备音频和转录的数据集。人工转录是繁琐的工作,有时会导致大量音频的问题。因此,就有了对半监督培训的积极研究,并为识别者建立了适当程度的信心。
由于深度学习与语音识别相结合,因此对CPU和内存的占用量不容小觑。随着用户大量采用语音识别系统,构建经济高效的云解决方案是一个具有挑战性的重要问题。对如何降低计算成本并开发更有效的解决方案的研究一直在进行。今天,大多数语音识别系统都是基于云的,并且具有必须解决的两个具体问题:延迟和持续连接。延迟是需要立即响应的设备(如机器人)的关键问题。在长时间监听的系统中,由于带宽成本,持续连接是一个问题。因此,还需要对边缘语音识别的研究,它必须保持基于云的系统的质量。
解决语音识别问题
近年来,语音识别的表现和应用出现了巨大的飞跃。我们离完全解决这个问题还有多远?答案也许五年、也许十年,但仍然有一些挑战性的问题需要时间来解决。
第一个问题是对噪音的敏感性问题。一个语音识别系统在非常接近麦克风而且不嘈杂的环境中运行得很好——然而,如果说话的声音比较远或者环境很嘈杂能迅速降低系统的效能。
第二个必须解决的问题是语言扩展:世界上大约有7000种语言,绝大多数语音识别系统能够支持的语言数量大约是八十种。扩展系统带来了巨大的挑战。
此外,我们缺少许多语言的数据,而且匮乏数据资源则难以创建语音识别系统。
结论
深度学习在语音识别和对话式AI领域刻下了深深的印记。而鉴于该技术最近获得的突破,我们真的正处于一场革命的边缘。
而最大的问题在于,我们是否准备赢得语音识别领域的技术挑战,并像其他商品化技术一样开始运用它呢?或者说,是否还有另一个新的解决方案正等待着我们去发现?毕竟,语音识别的最新进展只是未来科技蓝图的一小块:语言理解本身就是一个复杂而且或许更加强大的一个领域。


