2015年10月份,微软建设了世界上最安静的实验室,以加大消费类声学产品的研发力度;几乎同时,苹果也收购了VocalIQ以增强Siri的语音助手功能,特别是汽车领域的应用。随后,谷歌以7500万美元入股了国内的语音助手出门问问。而且,不到三个月,微软再次出手,将语音助手微软小娜推广到IOS和Android平台。

自科大讯飞上市以来,语音识别这项技术持续火热,但是语音识别却并没有改变我们的生活,而且我们更倾向于把这项技术作为娱乐消费。随着智能家居和汽车互联的兴起,语音交互的焦点很快转移到语音助手领域,语音助手将着重解决语音识别之后的语言理解问题。
这似乎距离我们自然人机交互的目标越来越近,但好像还缺点什么?对了,就是声纹识别,也就是人机自然交互的前提是首先要知道交互的对象是谁。明确了交互的对象,这才更有利于机器理解人们的语言并且做出智能应对。那么,声纹识别会是继语音识别、语音助手之后,语音交互的下一个风口吗?

首先看看什么是声纹识别,声纹识别是通过对一种或多种语音信号的特征分析来达到对未知声音辨别的目的,简单的说就是辨别某一句话是否是某一个人说的技术。
该项技术最早是在40年代末由贝尔实验室开发,主要用于军事情报领域。随着该项技术的逐步发展,60年代末后期在美国的法医鉴定、法庭证据等领域都使用了该项技术,从1967年到现在,美国至少5000多个案件包括谋杀,强奸,敲诈勒索,走私毒品,赌博,政治腐败等都通过声纹识别技术提供了有效的线索和有力的证据。

声纹识别的理论基础是每一个声音都具有独特的特征,通过该特征能将不同人的声音进行有效的区分。
这种独特的特征主要由两个因素决定,第一个是声腔的尺寸,具体包括咽喉,鼻腔和口腔等,这些器官的形状,尺寸和位置决定了声带张力的大小和声音频率的范围。
因此不同的人虽然说同样的话,但是声音的频率分布是不同的,听起来有的低沉有的洪亮。每个人的发声腔都是不同的,就像指纹一样,每个人的声音也就有独特的特征。

第二个决定声音特征的因素是发声器官被操纵的方式,发声器官包括唇,齿,舌,软腭及腭肌肉等,他们之间相互作用就会产生清晰的语音。而他们之间的协作方式是人通过后天与周围人的交流中随机学习到的。人在学习说话的过程中,通过模拟周围不同人的说话方式,就会逐渐形成自己的声纹特征。
因此声纹就像指纹一样,很少会有两个人具有相同的声纹特征。美国几个研究机构已经表明在某些特点的环境下声纹可以用来作为有效的证据。并且美国联邦调查局对2000例与声纹相关的案件进行统计,利用声纹作为证据只有0.31%的错误率。目前利用声纹来区分不同人这项技术已经被广泛认可,并且在各个领域中都有应用。

下面我们再看看声纹识别常用的方法,包括模板匹配法,最近邻方法,神经元网络方法,VQ聚类法等。虽然处理手段不同,但基本原理是类似的。一般都是将一维的声音信号通过短时傅里叶变换得到二维的语谱图。语谱图是声音信号的一种图像化的表示方式,它的横轴代表时间,纵轴代表频率,语音在各个频率点的幅值大小用颜色来区分。说话人的声音的基频及谐频在语谱图上表现为一条一条的亮线,再通过不同的处理手段就可以得到不同语谱图之间的相似度,最终达到声纹识别的目的。
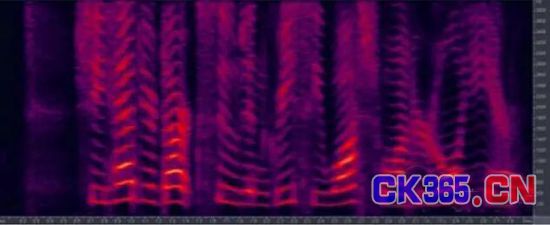
最后我们也要数数声纹识别的问题,上面说到了声纹识别的唯一性其实很好,但实际上我们现有的设备和技术仍然很难做出准确分辨,特别是人的声音还具有易变性,易受身体状况、年龄、情绪等的影响。另外,若在环境噪音较大和混合说话人的环境下,声纹特征也是很难提取和建模的。
虽然深度学习带给语音交互极大的提升,谷歌甚至开源了人工智能算法,但是声纹识别的研究进展仍然不大,这仍然受制于语料的采集和特征的建立。尽管市面上如科大讯飞也发布了声纹识别应用,但是还鲜有成熟的应用场景,智能家居曾被认为是最有可能的突破,但是随着声纹锁的饱受诟病,这个概念似乎也冷却了不少。但是人们追求自然人机对话的目标不会变,声纹识别作为其中的关键技术,特别是随着机器人技术的发展,必然会迎来一股新的市场热潮和应用。


