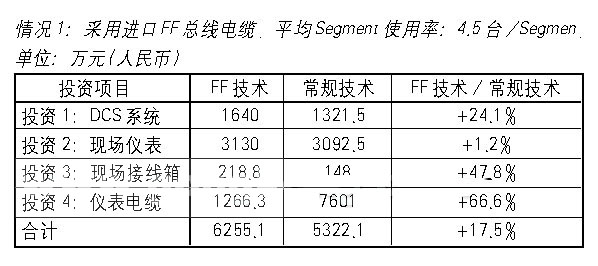
基于驱动程序的协议栈设计,相比于传统的基于任务的协议栈设计来说有两点好处:(1)效率更高;(2)对于有多个协议栈的系统来说,有更大的兼容性。 协议栈是指网络中各层协议的总和,其形象的反映了一个网络中文件传输的过程:由上层协议到底层协议,再由底层协议到上层协议。使用最广泛的是英特网协议栈。协议栈是指网络中各层协议的总和,其形象的反映了一个网络中文件传输的过程:由上层协议到底层协议,再由底层协议到上层协议。使用最广泛的是英特网协议栈,由上到下的协议分别是:应用层(HTTP,TELNET,DNS,EMAIL等),运输层(TCP,UDP),网络层(IP),链路层(WI-FI,以太网,令牌环,FDDI等),物理层。 1 基于任务的方式 在我们比较两种设计方式的技术细节之前,我们必须了解它们。传统的设计方式包括将协议栈置于实时操作系统或内核之上,但是大多数实时操作系统不提供网络互连的框架。所以,协议栈的设计者们不得不利用实时操作系统提供的机制--Task.图1说明了如何利用任务来实现一个三层间通信的协议。每一层被作为一个单独的任务,外加任务间通信机制负责传送数据和控制包上下通过协议栈,程序设计者负责定义层与层之间的接口和一个应用程序接口(API),以利于应用程序员传送和接收数据。

在这里存在几个效率不高的来源:首先,正如图1中点线所说明的,当包在应用程序、上层的通信协议,以及网络接口的设备驱动程序之间交换时,下层的操作系统正忙于上下文切换,每一次实时操作系统挂起其中一个任务,恢复执行另一个任务,时间都浪费在存取任务上下文中,考虑到每一个包无论是发还是收,都要通过协议栈的每一层,上下文切换的确造成了巨大的浪费。另外,当数据和控制包在应用程序任务和网络接口之间流动时,包含此类信息的缓冲区必然重复在任务间通信队列加入或删除。然而,这个系统开销是很大的,这本身是由于系统在队列操作时必然包括需与中断和上下文切换隔离的临界区。因此,不仅时间浪费于队列操作,而且整个系统对一些重要的事件例如中断的响应变得延迟。 2 基于驱动程序的方法 英文名为"Device Driver",全称为"设备驱动程序"是一种可以使计算机和设备通信的特殊程序,可以 说相当于硬件的接口,操作系统只有通过这个接口,才能控制硬件设备的工作,假如某设备的驱动程序未能正确安装,便不能正常工作。 因此,驱动程序被誉为" 硬件的灵魂"、"硬件的主宰"、和"硬件和系统之间的桥梁"等。 另外一种选择是将协议栈各层置于实时操作系统之中,图2说明了基于此种方案,同样的三层间通信协议是如何实施的。两者之间的显着区别在于:各个协议层是作为驱动程序模块,而不是任务来实现的。 另外一个改变在于:协议栈之上还有一个网络服务模块。加入这个模块的目的在于将与协议无关的网络特性抽象化。也就是说,它将应用程序设计者用来在协议栈间收发数据的应用程序接口(API)标准化,例如:你的嵌入式系统可能需要同时支持基于调制解调器接口的PPP连到一台远程计算机和一个红外接口用来与本地计算机通信。然而程序设计者不必为两个事件各自编程,它只需用网络服务模块提供API与其它计算机进行通信,唯一的区别在于通过哪个网络接口而已。
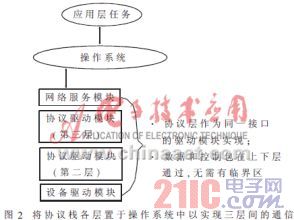
基于驱动程序方式的一个显着优点就在于上下文切换的次数仅仅是基于控制台应用程序的函数,并不基于协议层的数量。这样一来就可以减少实时操作系统保存和恢复任务上下文的次数,因而空出时间作更有意义的事,例如执行应用程序代码。 另一个好处在于,数据和控制信息更简单的在层与层之间传输,因为所有的协议层都处于同一个上下文中,所以相关的数据结构自动地为上下层所接受,结果你不必把他们在任务间队列中传送,由此产生的是,同时也避免了那些临界区系统由此可改进中断和优先级任务的响应时间。 3 缓冲区拷贝 缓冲区拷贝效率不高的第一个潜在因素在于:当数据在层与层之间传输时,数据缓冲区的分配、拷贝和释放,这与协议栈的结构无关,仅与缓冲区本身的结构有关。 一般来说,有两种常用的方式用于协议栈层与层之间传送数据,如图3所示。然而,这两种方式均有缺陷,我们假设,应用层有一些数据需要传送,通常我们把它称作消息,消息需被送至协议栈的最底层,因为在缓冲区中没有多余的空间来存放头尾信息,而协议层必须给数据本身加上头尾信息,协议层或分配一个足够大的缓冲区得以容纳消息本身和头尾信息,或分配两个小缓冲区,一个用于头信息,一个用于尾信息,然后用指针将三个缓冲区链接起来。
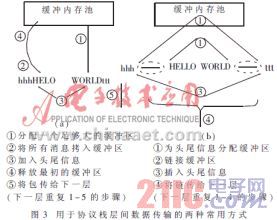
众所周知,每一层加入自己的头尾信息源于上一层传来的信息。因此,一个包在自上而下通过网络时,必须重复这一个过程许多次,时间被消耗于内存的分配之中(而自下而上则好得多,因为下层的头尾信息可以被上层忽略)。这种拷贝方式同时伴随着越来越大的消息,释放老缓冲区。链接方式虽然不涉及多余的拷贝,但是却将传输包的设备驱动程序代码复杂化。

另一种替代的方式与基于设备驱动程序的方式相当吻合,如图4所示。每次当协议栈创建或改变时,网络服务模块执行一个查询以确定整个协议栈的头、尾信息和最大传输单元要求,这样一来当应用程序向协议栈发消息时,网络服务模块相应地分配一些足够大容纳整个协议栈头尾信息的缓冲区,每一层仅仅将头尾信息填充至这些缓冲区,而不需内存分配或拷贝,这一机制对于性能有显着的改善。 重传缓冲区另一个效率不高的原因在于,协议层提供确认与重传机制,一个可靠的协议层的实现通常包括为每个包分配一个重传缓冲区,将包的内容拷贝至重传缓冲区中。如果远程系统的同一层确认了正确接收,重传缓冲区将被释放,然而,如果一个"NACK"发生,协议层重传缓冲区的内容,同时再分配一个重传缓冲区,拷贝内容至重传缓冲区。 如果已经发出的包可以被协议层标记为"Unmarked"或"Reserved"的话,上述机制就可被取消,这种情况仅保存一个指针而不拷贝。当设备驱动程序完成传送包并试图释放缓冲区,缓冲区系统确认此缓冲区保留,并不释放包,仅仅将它标记为"已传输",当相应的协议层收到确认(ACK)之后,就把包去掉标识,并且释放缓冲区,通过把这一特性固化至网络服务模块中,整个协议栈的效率将大大提高。 4 细节 任何合理的基于驱动程序的协议栈都会包含相似的数据结构、数据和控制原语及模块函数。下面介绍一下细节数据结构,以下是一些可能用到的数据结构。 (1)设备入口提供实时操作系统和某一特殊的协议模块的管道; (2)驱动程序静态变量对于每一协议层仅分配一次,不管协议层下的网络接口有多少,它是协议层的全局存储区域; (3)逻辑单位静态变量仅基于接口分配,所以如果你有一个设备驱动程序控制两个接口,就应有两个逻辑单位静态变量,但是仅有一个驱动程序变量和一个设备条目数据结构; (4)路径变量基于应用程序对协议的调用,仅分配一次。 基于上述四种定义,协议中的各种数据应被定义为最合适的类型,被选定的数据结构应当基于这个变量如何被使用:是被协议状态机所使用,还是接口或是应用程序,例如,一个特定的网络接口芯片在内存中的基址就应定义为逻辑单位静态变量。 5 函数

如果你正开发不止一个协议栈,编写一系列通用的函数会有帮助,表1、表2描述了一些基于驱动程序的协议栈框架的数据和控制传输原语及参数。