随着各大处理器处理速度的提高,特别是前几年Intel和IBM在CPU运行速度的竞争环境下,整个CPU运行速度的发展基本符合摩尔定律,但是近十年来,CPU的速度提升就变得十分缓慢了,个人认为最主要的原因有两点,其一就是工艺,其二就是访存,数据放在存取区域中,很难快速的load到core中。同样在各大设计应用中,存储器的IO速度问题越来越突出,那么到今天为止,在memory access上的的IO速度是否出现了一些突破呢?
Everspin’s nvNITRO NVMe card
上个月,Everspin公布了他们最新研发的基于MRAN而实现的 nvNITRO NVMe 存储加速器卡,吸睛之处在于他们给出了这款加速器卡的IO访存速度为:对于随机混合4KB 70/30的读写操作它的IO速度可以达到1.46百万,这个速度有点委实有点惊人,可是说这个速度在目前的IOPS界应该是最快的了。换句话说这个IOPS速度其实已经超过Intel 的P4800X Optane SSD卡将近三倍了(Optane在随机4KB 70/30 读写操作时的IOPS可以达到500K的速度)。究其缘由,有多个因素造就了如此高的IOPS速率,首先这款nvNITRO存储加速器卡采用了Everspin最新的高速1Gb ST-MRAM(Spin Torque Magnetostrictive RAM),DDR4,SDRAM兼容性IO;其次,加速卡内部为NVMe 1.1+ 配置了兼容的MRAM专用存储控制IP块;关键的是还采用了Xilinx Kintex UltraScale KU060 FPGA芯片为整个板卡实现了MRAM控制器到 PCIe Gen3X8的主机接口,这一点就为IO的高速 access奠定了基础。同时值得关注的是,Everspin的nvNITRO NVMe卡将会在2017年的Q4上见到,并且其可用能力将会达到1或2GB,值得期待。

图1:Everspin’s nvNITRO NVMe card
不同于过去实现NVMe 卡时采取的存储技术,非易失性MRAM实现了一些十分有意义的优势,比如说它的非易失,可以省去后备电源的需求。除此之外,ST-MRAM有非常高的持久力,所以nvNITRO卡可以每天没有限制的进行写操作不会出error,这就省去在NAND Flash存储是要通过耗损平衡算法来为存储steal一些cycle的需要,同时,随着运行时间的延长在读写性能上并未有所降低。
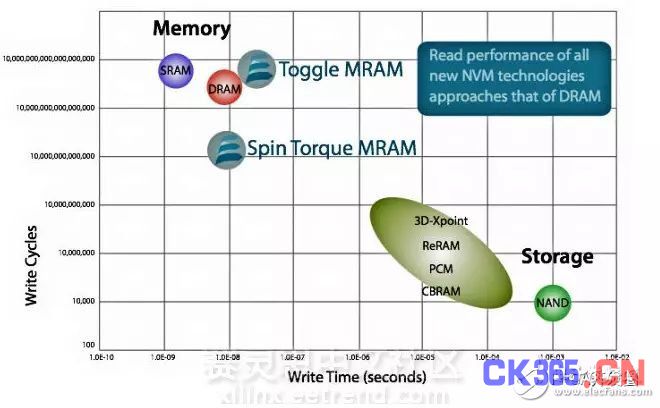
图:Everspin ST-MRAM 快速写且具有高的 write endurance
从上面的坐标系中,随着Y轴数据的增加,观察X轴上可以看到Everspin的ST-MRAM的写速度相当快,几乎和DRAM速度相同,当然了,这一点也确实是实现nvNITRO加速器具有相当快的读写速率的原因之一。
另外,关于Everspin nvNITRO NVMs 存储加速器的数据手册中值得指出的一点是“用户可以通过写自己的RTL code到可编程的FPGA芯片来自定义feature”(原文为:Customer-defined features using own RTL with programmable FPGA),这就好比说用户自己可以在nvNITRO 存储加速器卡系统中的Lintex UltraScale KU060 FPGA芯片中写code来实现PCIe接口和ST-MRAM控制器,即在不增加BOM开销的前提下,你可以写自己独特的需求code在这个设计系统中。这样一说的话,如果身边有这样一块板子的话确实值得一试。
总结
在上面的整个介绍中,主要是突出了nvNITRO这个加速器卡的访存速度超级快,并对其快的原因进行了分析。其实结合以前的一些文章,可以发现并归纳出 一个关键点:使用FPGA其实是实现这些性能的一个前提,比如说应用FPGA可以灵活的实现各种数据接口和控制器;还有一点就是使用FPGA使得整个系统的灵活性完全不一样了,更多的为用户的自主设计流出了空间。相信在以后的更多用到Xilinx 高性能FPGA的设计中将会越来越注重将FPGA的灵活性发挥出来。