在人类语音的机器翻译领域内的进展还远远没有发展到为主流用户带来实质性好处的地步,与机器对话依然还不太顺畅。目前在低功耗音频技术方面的开发活动具有了改善这种永远是瓶颈的人-机交互关系的潜力,而这种先前曾阻碍了语音识别领域内真正进步的瓶颈将被突破。一条通往人-机互动领域内快速创新的道路正在开启,这将沿着我们与机器互动的方向引领诸多有趣的开发活动,这些机器将能够倾听我们,而且越来越多地听懂我们。
语音也许是人类最自然的交流方式,但是将一台机器引入到该过程则产生了对新的行为协议的需求,特别是在语音沟通过程中没有另一方持续视觉线索的时候更为重要。对于早期的用户,第一次电话通话是极不顺畅的;而且即使在今天,双向无线电台的断续通话方式也要求新用户进行一些调整。在这两种情况下,很快就发展出来一些常用的方法来实现相当自然的沟通方式,主要是因为通话的另一方也是人类。随着移动用户面临新的语音识别界面,他们将面临与使用那些很老的通信手段时所出现的类似挑战。
一个更近期的例子是,触摸屏革命展示出了它们如果能实现高品质同时具有可为用户体验带来附件价值的功能时,新的、陌生的、棘手的界面如何切入到主流应用并且受到欢迎。
因此值得去在一个比传统案例更为广泛的意义上去定义语音控制的“性能”。因而能够在考虑到下一代瓶颈时,设计出更多不会过时的解决方案。
构建一种高性能的语音识别解决方案
过去一直用非常简单的性能指标来评估语音识别解决方案。这些指标通常被换算为单独的“精度”或者“命中率”数值,从根本上来表述正确识别字和词组的概率。在定义“性能”时,需要一种更广泛的和深思熟虑的方式,它能够反映语音界面的长期发展潜力,以便向用户提供像触屏界面一样的舒适性和可用性等级。
翻译质量扮演了一个关键的角色,从根本上讲它是一种人工智能,远不止基本的字词识别。访问所有设备功能也使语音识别成为了触摸屏的一种切实可行的替代方案,有趣的是这也使该技术可用于一个更大范围的设备种类,包括像可穿戴技术这样更小的设备。低响应延迟以及一种自然的、“无协议的”的交互方式,以及即使在有噪音环境中也能很好地运行,也改善了体验。这要求精心的系统设计,以使设备级的信号处理技术能够与基于云计算的智能很好地结合,以将这些性能增强带给用户。
去除按键
语音识别目前最大的人体工程学局限性是需要进行按键或者其它机械性启动,从而限制了它在许多环境中的可用性。这种机械触发是功耗这一制约因素的终极结果。为了保持具有竞争力的电池寿命数值,移动设备中待机功耗的预算都极低,典型的电池电流值为单位数毫安。当功率预算这么低的时候,连续地运行语音识别(或者至少随意的语音识别)是不可行的。
到目前为止,一个按键触发器为这个问题提供了一种粗放的解决方案,它通过在按下按键之前禁用语音识别,使功率消耗平均值降到最低。但是,现今的语音触发功能作为一种特性正在被加载到最新的高端音频中枢(AudioHubs)上,因为OEM厂商希望语音识别功能能够更灵活、更易于使用。通过显著地降低语音识别的平均功耗数值,甚至降到待机模式预算范围内这样的水平,允许主处理器“休眠”。这种功耗降低(通常为一个数量级)是如此的显著,以至于可以完全消除对按键的需要。
语音触发器架构的选择
一次语音触发是一个简短的关键字或者词(例如“你好!手机”),它能够使设备被唤醒并且响应后面输入的语音。图1所示即为这种半自主的低功耗的“永远工作”的处理域,它为这种语音触发提供了一个平台。
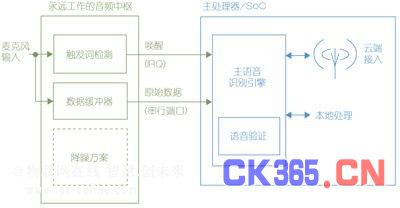
图1:使用了一个音频中枢的永远工作的语音触发。
音频中枢为语音触发功能提供了一个自然的中心,它带有通往所有内部功能和耳机麦克风端口的接口,并且在待机模式下通常也在运行,这是因为需要处理像附件接口监控其它原因。这个降低了系统中诸如时钟发生器和电压参考等常用基础功能的重复率,降低了静态功耗。音频中枢里针对语音唤醒的硬件优化使信号处理周期针对不同环境的噪声情况将被保持在绝对的最低值,将平均电池电流最小化。
可相互替代的架构分成两类:分离式解决方案和基于系统级芯片(SoC)语音的触发。其功率消耗情况和用户交互方式在很大程度上依赖于对这些架构的选择。软件架构,尤其是管理应用场景转换和串行端口配置的软件,也在确定交流方式中扮演着一个重要的角色。
基于系统级芯片(SoC)的语音触发器(如图2)往往因为主要的中央处理单元持续活跃而引起的非常高的静态功耗开销。这些解决方案的电池电流消耗通常比那些基于音频中枢的解决方案高出一个数量级。
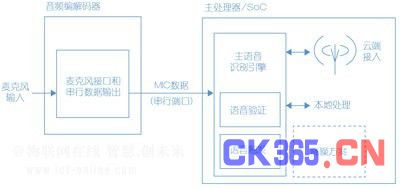
图2:基于SoC的语音触发模式。
分离式解决方案(如图3)通常使用来自主音频通道的不同的硬件接口。这有时可以导致音频不持续,原因在于应用场景转换管理和噪音抑制的启用/禁用等在不同的集成电路间,因为延迟和信号格式不同等因素而变得复杂。这些不连续有时会引起通话被中断,尤其是在转换到工作模式运行发生时,从而导致了对可听见提示的需要并限制了交流方式。在一些情况,因为连接到有限数量的麦克风也能限制其使用性(例如耳机麦克风的操作)。
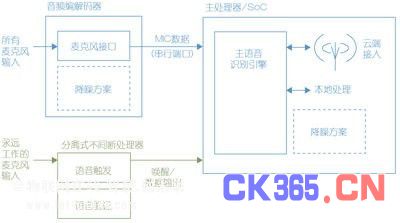
图3:分离式语音触发解决方案。
确保更好的用户体验
由于所有技术创新都是从根本上改变用户与消费电子设备交互的方式,衡量成功的真正标准是用户对他们所期望的改变的回应。参考触摸屏案例,新的语音控制技术的最终目标是它们应该成为下一代移动硬件可接受的和所预期的一项功能。我们将可能非常快就学会如何与新一代能够响应语音的机器进行交互,其方式与我们在触摸屏中开发出来的直观熟悉性大致相同,直到像触摸功能已经成为进入市场的新设备的一个标准功能这样的程度。
尽管如此,不同于较早的在远端也是人类的语音通信技术,仍然不确定的是用户在熟悉技术的行为特性后,是否将受益于与其设备进行了有用的或有趣的沟通。这在很大程度上取决于该技术的性能,但是今天用来衡量语音识别性能的标准仍然很粗放,并且不足以用来描述未来代系语音识别系统的有效性。考虑到更高级别的机器智能化、与系统其余部分的交互,以及与云计算的交互,还需要一种更广泛的方式。一种不会限制或者延迟下一代改善的音频架构,能够使这些性能跨越更加迅速地发生,很大程度上将不受硬件和低级别固件的限制。现在已经可以使用这种技术去构建移动设备。
低功耗音频中枢待机模式音频处理能力已经突破了语音识别可用性中一些最关键的瓶颈。虽然去除按键是一个重要的里程碑,但这只是可用于今天移动平台设计的许多语音识别提升中的一项。但在集成阶段选择了合适的架构,就可以支持一种完全自然的沟通风格,它极大地改变我们在未来几年使用移动设备的方式。