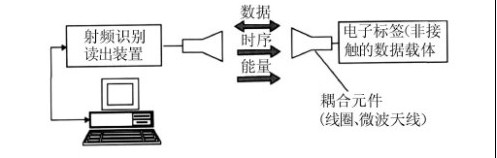
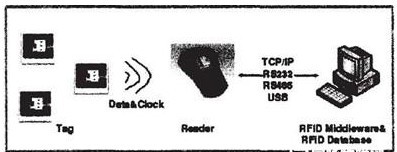
实现工业4.0或中国制造2025的前提之一是构建智能工厂,其核心要素包括了信息物理系统(CPS),物联网(IOT),智能认知,社交媒体,云计算与移动,以及M2M。 智能工厂构成了工业4.0的一个关键特征。智能工厂将从现在通过中央控制中?的模式转向通过自行优化和控制其制造流程来实现。
柔性生产的三个方面:
1.人、机器和资源如同在一个社交网络里自然地相互沟通协作。
2.生产出来的智能产品能够理解自?己被制造的细节以及将如何用。它们积极协助生产过程,回答诸如“我是什么时候被制造的”“哪组参数应被用来处理我”“我应该被传送到哪”等等问题。
3.机器和产品之间的数据传输将通过使用微处理器、存储装置、传感器和发送器来实现。这些装置将被嵌入至几乎所有可想象的机器、待加工产品、材料、智能工具和用于组织数据流的新型软件,由此实现产品和机器的相互通信并和交换数据。
大数据在智能工业的特征:
——数据的处理方法比数据本身值钱
无论是为促销产品还是作为战略目标的方式,大数据已然成为很多公司和机构过度使用的术语。2012年高德纳(Gartner)给出德大数据定义里面,特别强调大数据是多样化信息资产,不仅关注实际数据,而最最重要的是关注大数据处理方法。数据量大还是量小本身并不是判断大数据价值的核心指标,而数据的实时性(velocity)和多元性(variety)应该对大数据的定义和价值更具直接的影响。
——大数据是多结构化数据:包含人类和机器数据
我们大多数人会认为大数据包含了非结构化数据与结构化数据。我更提倡大数据是“多结构化数据”的说法,无论是自由文本还是关系数据库等,大数据可以由人类产生的数据足迹与机器自动生产的数据两大板块形成。大数据的工具和技术能够为不同的结构化数据服务。在信息化与工业化融合的过程与商业活动中,我们需要加强机器数据的采集,分析,并且把此项工作作为智能制造的核心工作之一。
——工业大数据的机器数据让我们的业务变得透明
在现代工业供应链中,随着大数据应用的普及,我们可以感受到了从采购,生产,物流与销售市场都是大数据的战场。大数据可以帮助我们实现客户的分析和挖掘,它的应用场景包括了实时核心,交易,服务,后台服务等。通过的载体包括了手机,传感器,穿戴设备,3D打印机和平板电脑等。传感器数据属于工业大数据类别之一,从这些机器数据中,我们可以保障生产,满足法律法规的要求,提升环保,改善客户服务。通过帮我们找到已经发生的问题做好协助预测相类似问题未来重复发生的几率与时间。
大数据的挑战:
1.用理性了解大数据
作为与工业4.0联系最为紧密的两化融合任务,中国制造2015其核心是生产过程、产品的智能化,以及互联网与制造业的融。数据的灵活处理性成为第一个焦点。随着传统数据库(database)和数据仓库(data warehouse)的运行越来越缓慢,并很难满足企业业务的发展需要,数据的灵活性就成为了推动大数据技术发展的一个重要推动力。
2.从Hadoop走向数据湖
2015年的大数据领域被看作是“数据湖(data lake)”与“数据藻泽”的状态之争。无论学术杰如何去诠释,其核心是强调一种基于对象的数据存储方式将收集来的数据以其最原生的格式(多结构化的)存储下来留作日后使用。“数据湖”具有很高的价值定位,它代表了一种可扩展的基础架构,非常经济且超级灵活。
3.自主大数据数据服务成为主流
随着大数据工具和服务的发展,2015年,IT行业将逐渐缓解发展瓶颈的局面,许多商业用户和数据科学家将会借助相关工具和服务访问大量数据。自助服务大数据将成为IT行业的一种趋势,它允许商业用户可以通过自助服务接触大数据。自助服务还可以帮助开发者、数据科学家和数据分析师直接进行数据探索和处理工作。当我们了解大数据的时候,业务的价值和IT的成本是我们主要衡量未来IT的标准,业务价值驱动大数据创新。Hadoop 不再成为我们讨论的大数据主题。我们需要了解更多的是业务创新,数据变现和业务场景的探索。
下一代的大数据体系——数据湖:
每个数据项都应有清楚的追踪,可追溯其源系统以及该数据项产生的时间等信息。2010年 JamesDixon以此理念,创造了数据湖(data Lake)这个术语,当时他打算将数据湖泊作为单一数据源来使用,而多数据源将形成“水景园”。尽管还是最初的构想,如今最普遍的应用是将数据湖泊当做许多数据源的结合。现有数据仓库在分析能力的缺失,业务对数据获取能力的提升,高级分析方法的创新是一种必然。
数据湖泊是近十年出现的术语,用来描述数据世界中,数据分析管道的重要组成部分。作为一个信息系统,数据湖泊是大型的基于对象的存储库,数据以其原始格式存储。通过全面的监控和分析,通过数据的分析模型的建立,学习,模拟,行动,最终实现内容认知的智能。 有并行体系以及无需移动数据即可对数据进行计算操作的明显特点。
特点 1 -数据湖泊是一个并行体系,能够存储大数据
数据湖泊的每个数据元素都有独特的标识符,并有一组扩展的元数据标签。
数据湖泊以数据源提供数据时的原格式(不论原格式是什么)存储原始数据。没有预设的数据模式,每个数据源都可以使用任何模式。由消费者根据自己的目的来理解数据。
特点 2 -数据湖体系无需移动数据即可对数据进行计算操作
总结:
大数据技术自身在快速的发展,从1.0到大数据3.0的数据湖时代,我们要理性的看待大数据,在关注数据量的同时,应该更加重视数据分析的能力和方法。笔者认为,实用分析工具与先进分析理念,真正释放数字化分析的力量,由人类轨迹产生的数据,与机器自动产生的数据得出洞见,从管理决策推导运营方案,最终实现数据价值提升。
业界有很多大数据的技术公司提供不同的技术,其中也包含了一大堆的开源软件开发出来的。大数据的成长路径一定是个长期成长过程。在不同的阶段,来打造不同的IT能力,我们倡导的是开放式大数据架构。不仅仅为大的数据集服务,同时企业中业务人员有很多小数据集的分析和探索。在很好满足业务的不同需求下,大数据一定是一种混搭技术,利用现有的IT投资来达到整个回报的最大化。特别在中国智能制造2025的变革中,数据湖不会是数据仓库和BI平台的终结者,但数据湖一定是未来企业数据技术(DT)的核心纽带,成为引导中国制造2025变革的数字宠儿。