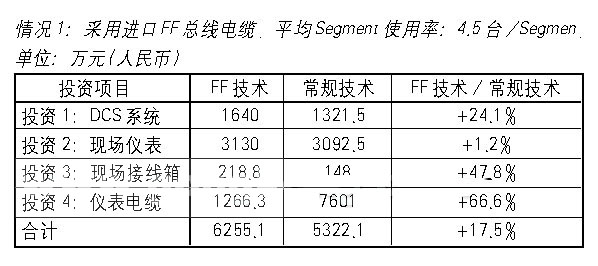
构建高速下一代网络通信设备的设计团队都会面临存储器带来的一系列制约因素。一些设计方案中仅使用片上存储器,而这种存储器本身容量有限,而且还会占用本可用于实现计算或其他功能的硅片面积。更加复杂的应用需要使用外部存储器,而且在如今的处理速率下,需要以尽可能高的随机访问速率访问存储器。传统的存储器接口由于速度慢、时延长、引脚数目多,会对性能造成负担。因此,传统的使用外部存储器的设计方案已经到达了收益递减阶段。
串行协议及标准打破I/O瓶颈
放眼当今所有可用的最新片上系统(SoC),除了针对传统存储器IC的接口外几乎所有的接口都是串行的。展望未来,向串行存储器的过渡也已经开始,因此,是时候决定支持哪些串行接口协议了。所有接口都可被划分为物理层或PHY,传输协议或物理编码子层(PCS),以及事务层或命令集标准化工作可以在各级分别进行。
关于串行PHY,行业标准组织光互连论坛(OIF)于2011年9月发布了通用电气接口I/O(CEI)标准,其中包括CEI-11标准(参考文献1)。而OIF等标准制定组织则需要三到五年的时间来制定信道模型,设置时钟和抖动预算,确定电信号编码以及鼓励生态系统开发。因此,这些标准正在被广泛应用到一系列应用中。
事实上,Giga Chip接口(GCI)(参考文献2)、Interlaken Look-Aside(ILA)(参考文献3)及混合存储器立方体接口(HMC)(参考文献4)这三种串行存储器接口协议已经采用了CEI-11物理定义,如图1所示。设计团队有望在将来看到这些协议同样符合CEI-255标准。三种串行协议的功能和主要特点如图2,这些协议分别针对不同的应用和市场,如表1所示。



因此,设计人员无需为多种用途专门开发三种不同的接口解决方案。相反,主处理器能够将运行在同一物理层上的两个或两个以上协议整合在一起。接口不必受存储器限制,但也能用于一般的串行I/O,赋予了系统设计人员最大的灵活性去解决一系列广泛的市场应用问题。
尽管可以多路复用多个协议,但是深入探究我们会发现还是存在明显的性能差异。将其他应用中使用的协议用在点对点应用(例如一个高性能存储器接口)中会导致不必要的开销和延迟。就近期而言,为了支持不同制造商生产的器件及性能水平,可能需要让SoC处理器包含上述三种串行协议。如果客户想要整合成两个或一个接口,那么,只有GCI能够为所有用于高性能网络线卡上的存储器访问模式提供一种高效率的串行协议。
了解网络线卡的要求
根据所实施的功能,网络应用一般包括三种存储器访问模式。第一种是缓冲应用,读写比率固定为1:1,数据存留时间短。数据包到达后需要存储一小段时间,才能被派发到下一个节点。根据终端市场的不同,在队列中数据包缓冲区可能具有也可能不具有纠错功能。如果由于某种原因数据包被损坏,网络中一般自带丢弃该数据包并触发从源头重发的选项。数据包缓冲过程的类型包含封包低于64B的高封包到达率类型,和大型或特大(9KB)封包发送的长持续大象流 (elephantflow)类型。效率是非常重要的,但支持各种报文大小的能力也是必要的。图3比较了数据包缓冲应用中的数据传输效率,包括所有必要的命令和传输开销。
存储器的第二个重要用途就是查找应用。在查找应用中,表格会偶尔被写入和更新,但却以极高的随机速率进行读取,且访问范围很小(约4~8个字节)。对包头处理来说,这可能是针对每个封包的多次查找。数据持续时间长,且由损坏导致的任何中断都会使通信流发生中断。在大多数情况下,查找表会使用错误校正码(ECC),以保护存储器中的内容。DRAM存储器的随机访问速率往往要低于单个40G端口的封包到达率。为了模拟一个更加快速的查找表,可以制作多份表格副本,然后用循环方式访问这些副本。两个表格副本的表格复制,效率还相当高,如果复制数量超出两个,则效率会迅速降低,从而限制了该技术的有效性。这也就凸显了查找应用对高访问速率存储器器件的需求。
仅考虑查表应用的串行接口时,回传或读取通道就成为了瓶颈,因此,实现回传通道传输效率最大化就成了重中之重。图4描述了三种不同协议下的数据回传效率。
包头处理中的第三个应用要求进行真随机读写访问。在过去,只有SRAM能够实现这一性能。而如今,MoSysMSR720拥有创新型存储体冲突解决 (Bank-Conflict Resolution)逻辑,使其能够对任意地址进行同步读写访问,同时还可维持完整的数据一致性。查找与随机访问这两种功能需要高效率和小数据字传输,可以通过GigaChip接口来解决这些问题。如表1所示,GCI的CRC位是以每帧为基础进行的,因此将小数据字传输的开销降到了最低。GCI可以用最少的开销支持最低的有效载荷,是小型访问传输的理想选择。
电路板级的最佳节约方案
目前为止,存储器向串行接口转变的前提突出了性能优势,但同时也节约了大量成本。很简单,高效串行数据传输增加了每个引脚的带宽密度,转而减少了引脚数量,并降低了电路板复杂度和每位传输消耗的能量。串行接口具有低功耗优势,因此还可以从整体上降低热量输出。
串行互连的电路板布局方案可以减少被路由的信号数量,进而减少电路板叠层结构中的层数。同时,这也降低了电路板的铜消耗量,并缩小了电路板的面积,进而显著地降低了成本。串行通信还可以实现更远距离的互连,使热与机械问题与主机分离开来。总而言之,串行通信的效率和性能可以让设计方案更具成本效益。
但遗憾的是,串行解决方案的实施却一直受到流言的阻碍,其中流传最广的就是串行化/解串行化延迟、功耗和误码率。而串行接口在存储器应用中的出现和使用证明了串行解决方案的可行性。MoSys推出的第二代带宽引擎(Bandwidth Engine)IC(BE-2)进一步打破了这些对串行解决方案的误解,BE-2的读取延迟仅为12ns,与最高性能的低延迟DRAM可比。但一个副效应就是增加了缓冲需求,进而增大了延迟,使之陷入一个恶性循环。因此,存储器和接口的延迟都会在很大程度上影响到系统的整体设计。
尽管传统的SRAM也可能具有低延迟的特点,但BE-2能够在有效的读写速率下实现连续数据回传,且该速率要高于SRAM许多倍。从内部来看,BE-2的创新型Bandwidth Engine架构能够支持16路并发存储器访问。而这一性能仅可在具有串行接口的主机上实现。相比之下,传统SRAM尽管具有低延迟的优点,但其访问和带宽仍受限于并行总线接口,同时,传统SRAM也缺乏容纳多条100G链路所需的空间。简而言之,对于高效的高吞吐量网络应用来说,串行解决方案可以为数百 G系统提供唯一的发送通道(如图4所示)。而三种串行协议中,GCI协议的数据回传效率最高。
对于给定的制造技术来说,更高性能就意味着要增加功耗。在这种情况下,功率也许较高,但功率性能比却较低。而GCI协议的高传输效率会带来相应的高能源利用效率,并提供产生高吞吐量的方法。甚至对于那些使用多芯片模块技术(包含内置存储器)制成的SoC来说,也可从高效串行接口中受益。正如我们上面提到的,串行解决方案能够减少引脚数量,并降低电路板复杂度、面积和成本。
随着数据速率的提升和电信号电平的降低,无论接口是串行还是并行,抽样数据位错误的可能性增加了。对于在高频率下运行的网络接口来说,即使使用的是并行接口也需要进行一些错误校验和处理。而凭借高数据速率和更远距离的传输,串行接口中往往配置了确保数据完整性的机制。GCI可通过重放机制实现自动错误恢复;对于那些不耐网络抖动的应用来说,GCI还可提供主机错误恢复功能。CEI接口的低误码率加上GCI的错误校验和恢复功能就形成了一个强大的解决方案,适用于各种运营商级和企业级应用。
性能最高的网络存储器解决方案
MoSys推出的Bandwidth Engine满足了各种不同的系统设计要求,其高性能、串行连接的分立式IC器件与配套的处理器相结合,得以使网络解决方案发挥出最佳效力。其内部并行式架构设计可实现每秒60亿次访问,比传统的网络存储器要高六倍。这使之成为网络设施硬件中包头处理的理想解决方案。使用GCI协议的串行I/O效率,能够使器件在最广泛的有效载荷大小范围内实现这一水平的性能。
高系统可靠性
除了错误防护接口和ECC防护存储器阵列外,Bandwidth Engine架构还支持智能错误管理功能。该功能可提升运营商级与企业级网络设备的数据传输质量和可靠性,而特别之处在于,该功能还可预先制止错误。其自检与自我修复技术能够检测、移除并替换低于基线阈值的存储区域。这样一来,可以降低不可挽回的多位误码风险。此外,BandwidtEngine架构还支持后台内置自测试(BIST)、存储器刷洗(memory scrubbing)和存储器热备份(memory sparing),同时还能够进行持续自我修复。
结论
同时支持三种协议使设计人员得以调整外部元器件来实现系统的价格/性能目标。这样一来,设计团队就可以实现高重复利用度,从而减少整体设计工作量,缩小硅片面积,加快设计周期,并赋予最终产品更佳的灵活性,从而应对更大、更广范围内的终端用户市场。
对于高吞吐量网络设施硬件来说,串行芯片对芯片协议提供了唯一的可伸缩方法。GCI、ILA和HCM三种协议各自都针对不同的应用和使用实例进行了优化,但也可在处理器上将这三种协议结合在一起以实现最终所需的灵活性。GigaChip接口可以提供最好的颗粒度,最适合用于处理封包头,但也并不排除其在较高负载应用中的使用。GCI可以提供一个最优的点对点解决方案,并可为未来的高速率链路提供可伸缩性能。相比之下,传统的存储器解决方案已经到了性能伸缩性收益递减阶段。