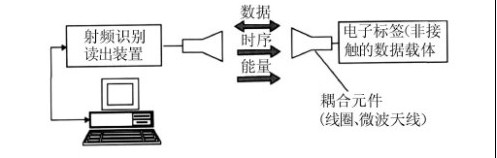
无线射频识别技术(RFID)是一种利用射频信号进行非接触自动识别的技术,广泛应用于物流、供应链管理、商业零售和交通运输等领域。RFID系统一般由具有电子编码(ID)的标签和阅读器组成,它们利用无线信道实现相互通信来交换信息。当系统中有多个标签同时向阅读器发送数据时,将会产生相互干扰,使阅读器不能正确接收信息,这就是标签碰撞。防碰撞算法能够有效解决标签的碰撞问题,实现阅读器高效、快速地读取标签信息。
目前主要存在两种类型的标签:有源标签和无源标签。前者通过电源提供能量来计算和发送信息,计算能力强,但使用成本高;后者通过接收阅读器发送的电磁波获得能量,计算能力有限,所以传统网络中的许多防碰撞技术难以直接应用,但较低的成本更利于其在RFID系统中推广使用。本文研究的是无源标签在RFID系统中的防碰撞问题,并基于ALOHA提出了一种改进算法,它能够迅速处理当前识别循环中发生的碰撞,从而有效降低此后在循环中发生标签碰撞的概率。仿真结果表明该方法效率较高,尤其在标签数量较大时相比动态帧时隙算法(DFSA)消耗时隙更少。
1 几种主要的防碰撞算法
目前,RFID系统中的标签防碰撞算法主要分为基于ALOHA的算法和基于树的算法两大类。基于ALOHA的算法是随机算法,该算法中标签利用随机时间响应阅读器的命令。此类算法主要有时隙ALOHA算法、固定帧时隙算法、动态帧时隙算法等,其中系统效率最高的是动态帧时隙算法(DFSA)。算法中的“帧”是由阅读器定义的一段时间长度,其中包含若干时隙,每个时隙长度等于标签的数据帧长度。在ALOHA算法中标签需要具备产生随机数的功能。
固定帧时隙算法是一种基本算法,每帧的时隙数相同。在开始识别时,由阅读器向作用范围内所有标签发送包含时隙数N的命令。标签收到命令后,将其时隙计数器置为1,开始记录时隙数,同时产生一个介于1和N的数作为其随机选择的时隙数值。当时隙计数器值与标签随机选择的时隙数值相同时,向阅读器发送应答消息。若标签被阅读器成功识别,则以后不再响应阅读器。一个帧结束后,阅读器开始识别时隙数同样为N的新帧。该算法虽然简单但识别效率不高,由于帧长固定,当标签数远小于时隙数时,会产生较多的空闲时隙,浪费系统资源;反之,则会产生过多的碰撞,大大降低系统效率。只有在标签数目与时隙数相差不大时,才会有较好的系统效率。由于该算法的时隙数不能随着标签数目的变化而改变,因此,无法获得稳定的系统效率。
动态帧时隙算法(DFSA)是一种改进的帧时隙算法,具有较高的效率。其每帧的时隙数会根据标签数目的不同而变化,主要执行过程如下:(1)阅读器估计在其作用范围内未识别的标签数目,从而决定下一帧需要的时隙数值N;(2)阅读器发送包含N个时隙的帧,标签随机选择一个时隙向阅读器发送应答消息,在此过程中已被成功识别的标签将不再响应阅读器。重复执行(1)、(2)的操作直至成功识别所有标签。该算法的效率在34.6%和36.8%之间[1]。
二进制树算法系统效率高,但系统的设计复杂。其算法的基本思想是:将处于碰撞的标签分为左右两个子集0和1,先查询子集0,如果没有碰撞,则正确识别标签,若仍然存在碰撞则再次分裂,把子集0分成00和01两个子集,以此类推直到成功识别子集0中的所有标签,再按上述步骤查询子集1。该算法虽然不存在错误判决,但是整个识别过程需要逐一检查标签ID前缀是否匹配,如果一个标签集中各个标签的ID非常相近,则完成整个识别过程需要花费过长的时间。
2 改进的方法
本文提出一种基于ALOHA协议的简单高效防碰撞算法,该算法能够迅速处理标签发生的碰撞。当发生碰撞时,系统会立刻开始一个新的识别过程,此时阅读器需要先估计发生碰撞的标签数目,然后向碰撞标签发送重新设置的时隙数值,而标签也会产生一个随机选择的时隙数值,当该随机数等于其时隙计数器时,向阅读器发送应答消息。如果在这个新的识别过程中再次发生碰撞,则重复执行上述步骤,这样可以减少如下情况的发生:当前发生碰撞的标签在下一次循环中可能再次发生碰撞从而在系统中产生更多的碰撞。
实验中假定有n个不同电子编码(ID)的无源标签,阅读器可以估计标签数目但是不知道其确切的值。设初始时隙数为Ni,当开始识别时,阅读器向所有标签发送包含Ni的消息,标签收到后将产生一个介于1和Ni之间的随机数,当标签的时隙计数器值与其随机产生的时隙数值相同时,将向阅读器发送应答消息。若此过程中没有发生碰撞,则阅读器就能成功识别标签。上述过程与ALOHA算法类似。但如果标签发生碰撞,阅读器则放弃之前已经成功识别的时隙,开始一个新的识别过程(此处假定阅读器和标签能够成功完成规定的动作)。在此过程中,阅读器估计发生碰撞的标签数目nc[2],通过nc来确定新设置的时隙数Nc,标签收到包含该数的消息后产生一个介于1和Nc之间的随机数,重复执行此过程直到不再发生碰撞。图1是本文方法的流程图,图中阅读器初始时发送包含Ni的消息,当发生碰撞时,能够迅速进行处理。剩余的标签将在第一组碰撞标签处理完成后再进行识别。
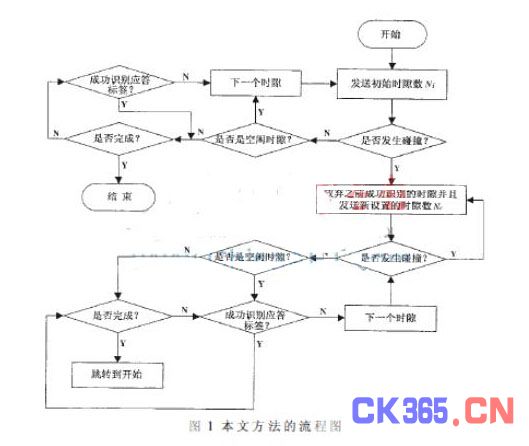
前面在描述DFSA算法时提到,阅读器会在第一轮识别完成后发送一个新设置的时隙数值给所有发生碰撞的标签,这些标签分别产生随机选择的时隙数。但是可以发现,第一轮识别中发生碰撞的标签同样可能在之后的识别轮次中再次发生碰撞,而本文的方法能够迅速处理标签的碰撞,降低碰撞标签以后再次发生碰撞的概率。阅读器本身无法知道发生碰撞标签数目,但是可以通过估计得到nc,由nc确定重新设置的时隙数值Nc并开始新的循环。为了获得较优的系统吞吐率,本文根据不同范围的标签数由表1来确定Nc[3]。
当未被识别的标签数目很少时就不需要采用过大的时隙数值,反之如果标签数目很多而时隙数过小时,则发生碰撞的概率将会增加。当设置的时隙数与需要识别的标签数目相等时,可以获得最大系统效率[4]。因此,选择合适的时隙数非常重要。在本文的方法中,将根据表1的数据来确定识别过程中不断改变的时隙数值。
为了执行本文的方法,需先定义一个特殊的命令“throw_away”,它表示开始执行该方法的各个步骤,程序1所示是阅读器需执行程序的伪码,描述了当阅读器检测到标签碰撞时将会发生的动作。当c>0时,表示发生碰撞,阅读器将发送throw_away命令给碰撞标签;ad是针对碰撞标签的计数值,当发生碰撞时,ad的值加1;在此之后阅读器将通过估计碰撞标签数目来确定Nc。
程序1 检测到碰撞时阅读器执行的程序
/*Reader:*/
/*发送”throw_away”命令*/
if (c>0) /* 发生碰撞*/
/* 阅读器发送throw_away命令给发生碰撞的标签 */
tag_respond = tag (throw_away);
if ( tag_respond > 0 ) /* 命令发送成功 */
ad = ad + 1; /*当发生碰撞时ad的值增加1 */
tag (ad); /* 将ad的值发送给标签 */
start a new round;
broadcast Nc;
程序2所示是标签需执行程序的伪码,描述了碰撞标签收到阅读器发送的throw_away命令后将会发生的动作。通过设置ct的值来限制碰撞标签应答阅读器,当标签接收到throw_away命令时其值加1;当标签随机选择的时隙数等于其时隙计数器值,并且ad与ct相等时,发送应答消息给阅读器,同时ct值置0,标签再次收到throw_away命令之前不再响应阅读器。
程序2 接收到throw_away命令时标签执行的程序
/* Tag: */
/* 从阅读器处获取初始参数 */
ct = 1;
transmission;
receive the number of slots;
generate random numbers;
if ( slot = = ti && ct = = ad )
transmit message; /* 标签发送应答消息 */
ct = 0; /* 发送完成后ct置0 */
if (receive “throw_away”)
ct = ct + 1;
goto transmission;
如果在最后一个时隙中发生标签碰撞,系统将会放弃之前已经成功识别的时隙。若此情况经常出现,则系统效率会降低很多,这是应用本文方法理论上可能会发生的最坏情况。图2的仿真结果是这种情况发生的概率,从中可以看出当标签数量较大时,这种最坏的情况发生概率其实很小。因此,当标签数目较多时,这种最坏的情况几乎不会发生,而应用本文的方法就可以减少识别过程中的时隙消耗。

3 仿真结果
大量标签向阅读器发送消息时产生碰撞,假定标签数从10增加到300,图3是应用本文方法进行仿真得到的结果。从中可以看出本文方法比DFSA算法耗费的时隙少,并且标签数目越多差别越明显。这表明对比DFSA算法,本文方法节约了时隙资源。

为获得较高的系统效率,仿真时设初始时隙数Ni为16,约为开始时的标签数目。可以通过改变初始时隙数Ni来观察所产生的影响,图4表明,当初始时隙数变为64时,即使标签数目增加,系统效率也不会有明显的变化;但标签数目较少时,较大的初始时隙数Ni对应较小的碰撞发生概率,此时,Ni=128时的系统效率比Ni=16和Ni=64时低。上述结果表明初始时隙数Ni设为16,可以应用于标签数较多的情况。
设初始帧长Ni为16,持续增加标签数目,仿真结果如图5所示。可以看出,当标签数持续增加时,本文方法耗费的时隙数明显小于DFSA算法;而当标签数较少时,这种差异并不明显。综上,本文提出的方法系统效率优于DFSA算法,并且耗费更少的时隙。
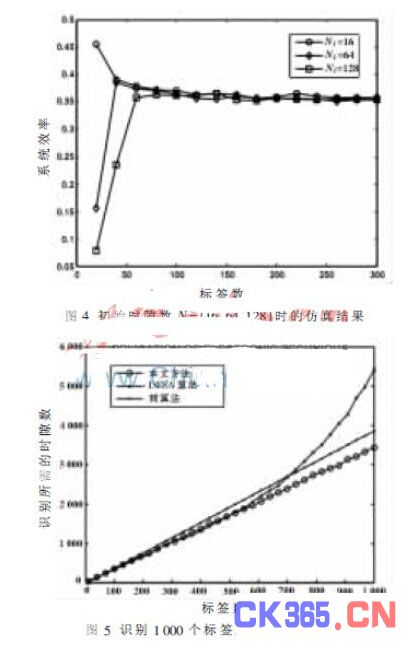
本文提出了一种基于ALOHA协议的简单高效RFID系统防碰撞算法。阅读器先给标签发送一个包含初始时隙数的消息,标签收到后随机选择一个时隙同时将自己的时隙计数器置为1。当标签随机选择的时隙数等于时隙计数器时,回复其电子编码(ID)给阅读器,如果发生碰撞,阅读器将放弃已经成功识别的时隙而开始新的识别循环,这样使碰撞标签能得到迅速处理。该方法中阅读器能够在新的识别循环中首先鉴别出碰撞标签,然后再识别其余的标签。当标签数增加到1 000时,本文方法比DFSA算法少耗费约54%的时隙,并且系统效率可以稳定在35%左右,相比DFSA算法此时约20%[5]的效率也有较大提高。