1 引言
近几十年来,计算机技术飞速发展,计算速度不断提高,内存容量不断增大;但同时,在科学研究和工程应用中越来越需要对大型舰只、车辆、航空航天器等目标进行电磁散射特性分析。这些目标电尺寸非常巨大,求解问题所含未知量动辄以百万、千万计,现有水平下单台PC机很难应对如此庞大的计算量。鉴于此,越来越多的科研、工程人员希望在改进算法的同时能够拥有高效的并行计算环境。巨型并行计算机存储容量大、运算速度快,但价格昂贵。网络并行计算应运而生,它是近几年国内外计算机科学研究与应用领域中最引人注目的前沿课题之一。网络并行计算以网络为基础,这种并行计算环境的显著优点是投资较少、灵活性强等。
作为数值方法,多层快速多极子法(MLFMA)具有数值误差可控、计算精度高、通用性强和应用范围宽的优点。它们对软硬件环境要求低,在一般的PC机即可开展复杂目标电磁仿真。目标散射分析能力主要受限于计算机内存大小。
一般情况下,MLFMA单机处理的未知量数目最大为40万左右。因此,降低并行MLFMA单机的内存需求,计算更大未知量的问题就成为我们的主要目的。MLFMA的内在并行性包括不变项求解中含有的内在并行性。我们很容易发现平移因子、聚合因子以及配置因子的计算都是独立的,可在多台计算机上异步进行。另外,用MLFMA求解矩阵矢量乘法时也存在内在并行性。
1997年,美国伊利诺依大学W.C. Chew教授与Demaco公司联合推出高效高精度电磁数值分析软件FISC,在伊利诺依大学超级计算机应用中心的SGI Cray Origin 2000型计算机上求解了203万未知量的散射问题,而且成功求解了VFY218模型飞机在8GHz平面波照射下的双站RCS,未知量高达999万。FISC正是基于MLFMA技术的。其后,S.V. Velamparambil、J.M. Song和W.C. Chew还开发了FISC的并行版本ScaleME,并行MLFMA得到了迅猛发展。在这种大趋势下,本文研究了网络并行计算技术在MLFMA中的应用,给出含240万未知量金属球的双站RCS曲线,初步测试、验证了并行求解大未知量问题的可行性与准确性。
2 并行多层快速多极子技术
我们依据如下步骤进行设计(可参见表1):
A. 读入数据,并对其分层分组
各计算进程同时读入RWG网格剖分信息,并为目标结构上的RWG单元建立八叉树结构。
建立八叉树结构的过程是:首先,选择能够包含该结构的最小立方体,即第0层盒子;然后,将这个盒子均分成8个子立方体,即第1层盒子;再将第1层盒子均分8部分得到第2层盒子;如此反复,直到最小盒子的边长为0.25λ~0.45λ。在各层盒子中,不包含基函数的盒子将被抛弃。
B. 划分任务
在保留原串行算法中八叉树结构的基础上,在适当层上将整棵树划分为多个子树,并以子树为基本单位划分任务给各个从机。
例如,我们将第1层的8个盒子分配给8个从机分别进行处理,此时我们区分出各个从机所要各自处理的各层非空盒子,并单独编号,完成其与全局各层非空盒子之间的相互索引。
C. 近场矩阵填充及远场不变项处理
初始化各从机处理的近场矩阵,给出各从机近场矩阵的大小及非零元素位置的索引。
用MLFMA生成的近场矩阵一般都是稀疏化的,如果直接存储会造成内存的浪费,所以要把稀疏化矩阵压缩存储。稀疏化矩阵压缩存储一般有两种方法:行压缩存储和列压缩存储.,我们采用行压缩存储。
远场不变项的处理主要涉及当前层的转移因子,父子层之间的平移因子。由于它们占用内存相对较小,我们可以预先计算这些远场不变项,需要时即可直接调用。
表1 并行MLFMA的主机及从机流程比较

D. 矩阵矢量乘的处理
首先,各从机计算本地存储的近场矩阵与电流未知量的乘积,再发送至主机汇总进行处理比较,然后进行其他运算。
3 MPI软件包及网络并行计算技术
MPI(Message Passing Interface)是消息传递并行程序设计标准之一。指定该标准的主要目的是为了提高并行程序的可移植性和使用的方便性。有了标准,并行计算环境下的应用软件库以及软件工具就可以透明的移植。各个厂商可以依据标准提供独具特色和优势的软件实现和硬件支持,从而提高并行处理的能力。
我们选用国内外较流行的MPICH2版本与Compaq Visual FORTRAN 66相结合进行并行程序设计。MPICH2具有通用性强、系统规模小、成熟度高、可以免费获得等优点,非常适合数值计算。
使用主从结构模式实现并行MLFMA,主机主要功能为初始化、任务的管理分配和最终结果的输出,不参与具体计算;中间计算由从机负责。
并行算法可以用很多标准来评价,如加速比和并行效率[7,8]。
加速比定义为
并行效率定义为
搭建高性能高效率的并行计算机网络平台,计算机主要配置为Pentium IV双核1.86GHz CPU,2GMB内存,Microsoft Windows XP操作系统,千兆以太网交换机。我们开发的并行多层快速多极子程序,用9台计算机参加并行计算,其中1台为主机,参加实际计算的为8台从机。
4 数值结果
算例一:入射波频率为1.6GHz,金属球直径17.067λ,未知量数目为172,680,计算出其双站RCS曲线,见图1。为了使曲线简洁明了、易于辨认,仅给出0°~30°部分。计算结果与Mie解吻合较好。由表Ⅱ中数据算得并行加速比为7.78,并行效率为97%。
算例二:入射波频率为1.6GHZ,金属球直径85.333λ,未知量数目为2,402,328,计算出其双站RCS曲线,见图2。为了使曲线简洁明了、易于辨认,仅给出0°~30°部分。计算结果与Mie解吻合较好。每台从机内存消耗为1.6GB。
表2 串行、并行程序单机内存消耗及时间比较

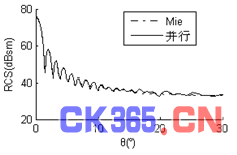
图1 (a) φ=0°时直径17.067λ金属球双站RCS曲线
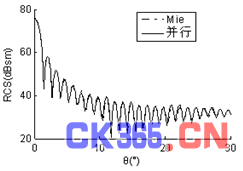
图1 (b) φ=90°时直径17.067λ金属球双站RCS曲线
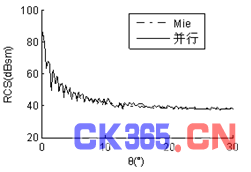
图2 (a) φ=0°时直径85.333λ金属球双站RCS曲线
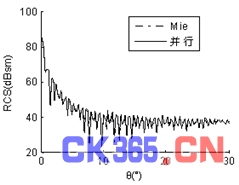
图2 (b) φ=90°时直径85.333λ金属球双站RCS曲线
5 结论
本文对网络并行计算在多层快速多极子法中的应用作了探求,计算了含240万未知量金属球的双站RCS,初步验证了并行求解大未知量问题的可行性与高效性。增多参与计算的从机数目,优化并行MLFMA,则能够计算更大规模的问题,这也是以后可以改进的方面。